Note
Go to the end to download the full example code.
MNIST Image classification
This script implements a model to classify the MNIST dataset. The model mainly consists of convolutonal layers and pooling layers with a few dense layers at the end. As the script is only for demonstration purposes, only 100 first datapoints are used to make the training faster. For a full example, change the parameter n to 60000. If n is increased, more epochs may need to be added and other hyperparameters tuned.
0.3%
0.7%
1.0%
1.3%
1.7%
2.0%
2.3%
2.6%
3.0%
3.3%
3.6%
4.0%
4.3%
4.6%
5.0%
5.3%
5.6%
6.0%
6.3%
6.6%
6.9%
7.3%
7.6%
7.9%
8.3%
8.6%
8.9%
9.3%
9.6%
9.9%
10.2%
10.6%
10.9%
11.2%
11.6%
11.9%
12.2%
12.6%
12.9%
13.2%
13.6%
13.9%
14.2%
14.5%
14.9%
15.2%
15.5%
15.9%
16.2%
16.5%
16.9%
17.2%
17.5%
17.9%
18.2%
18.5%
18.8%
19.2%
19.5%
19.8%
20.2%
20.5%
20.8%
21.2%
21.5%
21.8%
22.1%
22.5%
22.8%
23.1%
23.5%
23.8%
24.1%
24.5%
24.8%
25.1%
25.5%
25.8%
26.1%
26.4%
26.8%
27.1%
27.4%
27.8%
28.1%
28.4%
28.8%
29.1%
29.4%
29.8%
30.1%
30.4%
30.7%
31.1%
31.4%
31.7%
32.1%
32.4%
32.7%
33.1%
33.4%
33.7%
34.0%
34.4%
34.7%
35.0%
35.4%
35.7%
36.0%
36.4%
36.7%
37.0%
37.4%
37.7%
38.0%
38.3%
38.7%
39.0%
39.3%
39.7%
40.0%
40.3%
40.7%
41.0%
41.3%
41.7%
42.0%
42.3%
42.6%
43.0%
43.3%
43.6%
44.0%
44.3%
44.6%
45.0%
45.3%
45.6%
45.9%
46.3%
46.6%
46.9%
47.3%
47.6%
47.9%
48.3%
48.6%
48.9%
49.3%
49.6%
49.9%
50.2%
50.6%
50.9%
51.2%
51.6%
51.9%
52.2%
52.6%
52.9%
53.2%
53.6%
53.9%
54.2%
54.5%
54.9%
55.2%
55.5%
55.9%
56.2%
56.5%
56.9%
57.2%
57.5%
57.9%
58.2%
58.5%
58.8%
59.2%
59.5%
59.8%
60.2%
60.5%
60.8%
61.2%
61.5%
61.8%
62.1%
62.5%
62.8%
63.1%
63.5%
63.8%
64.1%
64.5%
64.8%
65.1%
65.5%
65.8%
66.1%
66.4%
66.8%
67.1%
67.4%
67.8%
68.1%
68.4%
68.8%
69.1%
69.4%
69.8%
70.1%
70.4%
70.7%
71.1%
71.4%
71.7%
72.1%
72.4%
72.7%
73.1%
73.4%
73.7%
74.0%
74.4%
74.7%
75.0%
75.4%
75.7%
76.0%
76.4%
76.7%
77.0%
77.4%
77.7%
78.0%
78.3%
78.7%
79.0%
79.3%
79.7%
80.0%
80.3%
80.7%
81.0%
81.3%
81.7%
82.0%
82.3%
82.6%
83.0%
83.3%
83.6%
84.0%
84.3%
84.6%
85.0%
85.3%
85.6%
85.9%
86.3%
86.6%
86.9%
87.3%
87.6%
87.9%
88.3%
88.6%
88.9%
89.3%
89.6%
89.9%
90.2%
90.6%
90.9%
91.2%
91.6%
91.9%
92.2%
92.6%
92.9%
93.2%
93.6%
93.9%
94.2%
94.5%
94.9%
95.2%
95.5%
95.9%
96.2%
96.5%
96.9%
97.2%
97.5%
97.9%
98.2%
98.5%
98.8%
99.2%
99.5%
99.8%
100.0%
100.0%
2.0%
4.0%
6.0%
7.9%
9.9%
11.9%
13.9%
15.9%
17.9%
19.9%
21.9%
23.8%
25.8%
27.8%
29.8%
31.8%
33.8%
35.8%
37.8%
39.7%
41.7%
43.7%
45.7%
47.7%
49.7%
51.7%
53.7%
55.6%
57.6%
59.6%
61.6%
63.6%
65.6%
67.6%
69.6%
71.5%
73.5%
75.5%
77.5%
79.5%
81.5%
83.5%
85.5%
87.4%
89.4%
91.4%
93.4%
95.4%
97.4%
99.4%
100.0%
100.0%
torch.Size([409, 1, 28, 28]) torch.Size([409, 10]) torch.Size([103, 1, 28, 28]) torch.Size([103, 10]) torch.Size([512, 1, 28, 28]) torch.Size([512, 10])
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]])
Model summary:
Input - Output: ((1, 28, 28))
Conv2D - (Input, Output): ((1, 28, 28), (32, 28, 28)) - Parameters: 320
ReLU - Output: ((32, 28, 28))
Add - (Input, Output): ((32, 28, 28), (32, 28, 28))
Conv2D - (Input, Output): ((32, 28, 28), (32, 28, 28)) - Parameters: 9248
ReLU - Output: ((32, 28, 28))
Identity - Output: ((32, 28, 28))
Add - (Input, Output): ((32, 28, 28), (32, 28, 28))
Conv2D - (Input, Output): ((32, 28, 28), (32, 28, 28)) - Parameters: 9248
ReLU - Output: ((32, 28, 28))
Identity - Output: ((32, 28, 28))
MaxPooling2D - Output: ((32, 14, 14))
Batch normalisation - Output: ((32, 14, 14)) - Parameters: 12544
Add - (Input, Output): ((32, 14, 14), (32, 14, 14))
Conv2D - (Input, Output): ((32, 14, 14), (32, 14, 14)) - Parameters: 9248
ReLU - Output: ((32, 14, 14))
Identity - Output: ((32, 14, 14))
Add - (Input, Output): ((32, 14, 14), (32, 14, 14))
Conv2D - (Input, Output): ((32, 14, 14), (32, 14, 14)) - Parameters: 9248
ReLU - Output: ((32, 14, 14))
Identity - Output: ((32, 14, 14))
Add - (Input, Output): ((32, 14, 14), (32, 14, 14))
Conv2D - (Input, Output): ((32, 14, 14), (32, 14, 14)) - Parameters: 9248
ReLU - Output: ((32, 14, 14))
Identity - Output: ((32, 14, 14))
MaxPooling2D - Output: ((32, 7, 7))
Batch normalisation - Output: ((32, 7, 7)) - Parameters: 3136
Add - (Input, Output): ((32, 7, 7), (32, 7, 7))
Conv2D - (Input, Output): ((32, 7, 7), (32, 7, 7)) - Parameters: 9248
ReLU - Output: ((32, 7, 7))
Identity - Output: ((32, 7, 7))
Add - (Input, Output): ((32, 7, 7), (32, 7, 7))
Conv2D - (Input, Output): ((32, 7, 7), (32, 7, 7)) - Parameters: 9248
ReLU - Output: ((32, 7, 7))
Identity - Output: ((32, 7, 7))
Add - (Input, Output): ((32, 7, 7), (32, 7, 7))
Conv2D - (Input, Output): ((32, 7, 7), (32, 7, 7)) - Parameters: 9248
ReLU - Output: ((32, 7, 7))
Identity - Output: ((32, 7, 7))
Conv2D - (Input, Output): ((32, 7, 7), (8, 7, 7)) - Parameters: 2312
ReLU - Output: ((8, 7, 7))
Batch normalisation - Output: ((8, 7, 7)) - Parameters: 784
Dropout - Output: ((8, 7, 7)) - Keep probability: 0.7
Flatten - (Input, Output): ((8, 7, 7), 392)
Dense - (Input, Output): (392, 200) - Parameters: 78600
ReLU - Output: (200)
Dense - (Input, Output): (200, 10) - Parameters: 2010
Softmax - Output: (10)
Total number of parameters: 173690
Epoch: 1 - Metrics: {'loss': '9.1475', 'accuracy': '0.0978', 'val_loss': '9.0377', 'val_accuracy': '0.0971'}
Epoch: 2 - Metrics: {'loss': '7.4317', 'accuracy': '0.1027', 'val_loss': '7.1494', 'val_accuracy': '0.0971'}
Epoch: 3 - Metrics: {'loss': '5.0784', 'accuracy': '0.1198', 'val_loss': '4.8808', 'val_accuracy': '0.1262'}
Epoch: 4 - Metrics: {'loss': '3.5678', 'accuracy': '0.1247', 'val_loss': '3.4583', 'val_accuracy': '0.1553'}
Epoch: 5 - Metrics: {'loss': '2.4567', 'accuracy': '0.1785', 'val_loss': '2.4486', 'val_accuracy': '0.2330'}
Epoch: 6 - Metrics: {'loss': '1.6430', 'accuracy': '0.4205', 'val_loss': '1.7033', 'val_accuracy': '0.4466'}
Epoch: 7 - Metrics: {'loss': '1.1709', 'accuracy': '0.6137', 'val_loss': '1.2493', 'val_accuracy': '0.6311'}
Epoch: 8 - Metrics: {'loss': '0.8938', 'accuracy': '0.7359', 'val_loss': '0.9796', 'val_accuracy': '0.7184'}
Epoch: 9 - Metrics: {'loss': '0.6822', 'accuracy': '0.8435', 'val_loss': '0.7699', 'val_accuracy': '0.8058'}
Epoch: 10 - Metrics: {'loss': '0.5457', 'accuracy': '0.8851', 'val_loss': '0.6452', 'val_accuracy': '0.8447'}
Epoch: 11 - Metrics: {'loss': '0.4554', 'accuracy': '0.8973', 'val_loss': '0.5666', 'val_accuracy': '0.8835'}
Epoch: 12 - Metrics: {'loss': '0.3836', 'accuracy': '0.9193', 'val_loss': '0.5113', 'val_accuracy': '0.9029'}
Epoch: 13 - Metrics: {'loss': '0.3222', 'accuracy': '0.9413', 'val_loss': '0.4724', 'val_accuracy': '0.9029'}
Epoch: 14 - Metrics: {'loss': '0.2651', 'accuracy': '0.9511', 'val_loss': '0.4337', 'val_accuracy': '0.9126'}
Epoch: 15 - Metrics: {'loss': '0.2150', 'accuracy': '0.9633', 'val_loss': '0.4004', 'val_accuracy': '0.9126'}
Epoch: 16 - Metrics: {'loss': '0.1715', 'accuracy': '0.9780', 'val_loss': '0.3673', 'val_accuracy': '0.9126'}
Epoch: 17 - Metrics: {'loss': '0.1420', 'accuracy': '0.9853', 'val_loss': '0.3408', 'val_accuracy': '0.9126'}
Epoch: 18 - Metrics: {'loss': '0.1209', 'accuracy': '0.9878', 'val_loss': '0.3217', 'val_accuracy': '0.9126'}
Epoch: 19 - Metrics: {'loss': '0.1019', 'accuracy': '0.9878', 'val_loss': '0.3123', 'val_accuracy': '0.9126'}
Epoch: 20 - Metrics: {'loss': '0.0866', 'accuracy': '0.9878', 'val_loss': '0.3068', 'val_accuracy': '0.9126'}
Epoch: 21 - Metrics: {'loss': '0.0733', 'accuracy': '0.9927', 'val_loss': '0.3090', 'val_accuracy': '0.9223'}
Epoch: 22 - Metrics: {'loss': '0.0631', 'accuracy': '0.9927', 'val_loss': '0.3116', 'val_accuracy': '0.9223'}
Epoch: 23 - Metrics: {'loss': '0.0539', 'accuracy': '0.9951', 'val_loss': '0.3160', 'val_accuracy': '0.9223'}
0.86328125
import torch
from torchvision import datasets
import matplotlib.pyplot as plt
from DLL.DeepLearning.Model import Model
from DLL.DeepLearning.Layers import Dense, Conv2D, Flatten, MaxPooling2D, Reshape, Add, Identity
from DLL.DeepLearning.Layers.Regularisation import Dropout, BatchNorm, GroupNorm, InstanceNorm, LayerNorm
from DLL.DeepLearning.Layers.Activations import ReLU, SoftMax
from DLL.DeepLearning.Losses import CCE
from DLL.DeepLearning.Optimisers import SGD, ADAM
from DLL.DeepLearning.Callbacks import EarlyStopping
from DLL.DeepLearning.Initialisers import Xavier_Normal, Xavier_Uniform, Kaiming_Normal, Kaiming_Uniform
from DLL.Data.Preprocessing import OneHotEncoder, data_split
from DLL.Data.Metrics import accuracy
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
torch.manual_seed(0)
torch.cuda.manual_seed(0)
n = 512 # 60000
train_set = datasets.MNIST(root="./data", train=True, download=True)
test_set = datasets.MNIST(root="./data", train=False, download=True)
train_images = train_set.data[:n]
train_labels = train_set.targets[:n]
test_images = test_set.data[:n]
test_labels = test_set.targets[:n]
train_images = train_images.unsqueeze(1).to(dtype=torch.float32, device=device)
test_images = test_images.unsqueeze(1).to(dtype=torch.float32, device=device)
train_images = train_images / train_images.max()
test_images = test_images / test_images.max()
train_labels = train_labels.to(dtype=torch.float32, device=device)
test_labels = test_labels.to(dtype=torch.float32, device=device)
train_images, train_labels, validation_images, validation_labels, _, _ = data_split(train_images, train_labels, train_split=0.8, validation_split=0.2)
label_encoder = OneHotEncoder()
train_labels = label_encoder.fit_encode(train_labels)
validation_labels = label_encoder.encode(validation_labels)
test_labels = label_encoder.encode(test_labels)
print(train_images.shape, train_labels.shape, validation_images.shape, validation_labels.shape, test_images.shape, test_labels.shape)
print(train_labels[:2])
model = Model((1, 28, 28), device=device)
model.train()
model.add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()))
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(MaxPooling2D(pool_size=2))
model.add(BatchNorm())
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(MaxPooling2D(pool_size=2))
model.add(BatchNorm())
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(Add(Conv2D(kernel_size=3, output_depth=32, initialiser=Kaiming_Normal(), activation=ReLU()), Identity()))
model.add(Conv2D(kernel_size=3, output_depth=8, initialiser=Kaiming_Normal(), activation=ReLU()))
model.add(BatchNorm())
model.add(Dropout(p=0.3))
model.add(Flatten())
model.add(Dense(200, activation=ReLU()))
model.add(Dense(10, activation=SoftMax()))
model.compile(optimiser=ADAM(learning_rate=0.001), loss=CCE(), metrics=["loss", "val_loss", "val_accuracy", "accuracy"], callbacks=(EarlyStopping(patience=3),))
model.summary()
history = model.fit(train_images, train_labels, val_data=(validation_images, validation_labels), epochs=25, batch_size=256, verbose=True)
model.eval()
test_pred = model.predict(test_images)
print(accuracy(test_pred, test_labels))
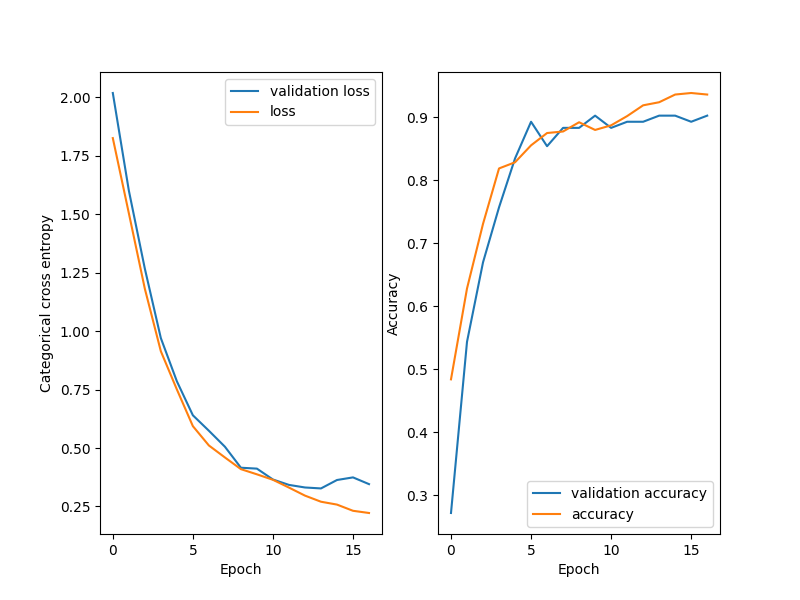
plt.figure(figsize=(8, 6))
plt.subplot(1, 2, 1)
plt.plot(history["val_loss"], label="validation loss")
plt.plot(history["loss"], label="loss")
plt.xlabel("Epoch")
plt.ylabel("Categorical cross entropy")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history["val_accuracy"], label="validation accuracy")
plt.plot(history["accuracy"], label="accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
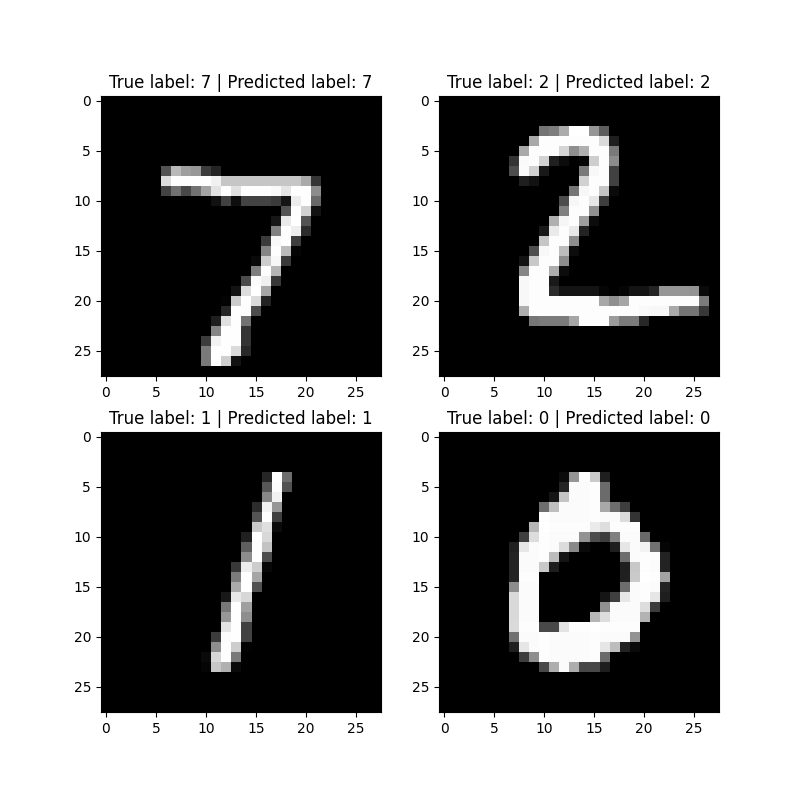
fig, ax = plt.subplots(2, 2, figsize=(8, 8))
ax = ax.ravel()
for i in range(len(ax)):
ax[i].imshow(test_images[i].numpy()[0], cmap='gray', vmin=0, vmax=1)
ax[i].set_title(f"True label: {test_labels[i].argmax()} | Predicted label: {test_pred[i].argmax()}")
plt.show()
Total running time of the script: (0 minutes 43.705 seconds)