Note
Go to the end to download the full example code.
Regression with neural networks
This script implements a model to predict values on a simple quadratic surface. It also showcases some regularisation methods like Dropout and BatchNorm.
Model summary:
Input - Output: (2)
Dense - (Input, Output): (2, 6) - Parameters: 18
Batch normalisation - Output: (6) - Parameters: 12
ReLU - Output: (6)
Add - (Input, Output): (6, 6)
Batch normalisation - Output: (6) - Parameters: 12
Dense - (Input, Output): (6, 6) - Parameters: 42
ReLU - Output: (6)
Identity - Output: (6)
Dropout - Output: (6) - Keep probability: 0.9
Dense - (Input, Output): (6, 6) - Parameters: 42
Batch normalisation - Output: (6) - Parameters: 12
Sigmoid - Output: (6)
Dense - (Input, Output): (6, 1) - Parameters: 7
Total number of parameters: 133
Epoch: 1 - Metrics: {'loss': '3.2712', 'median_absolute': '1.8340', 'val_loss': '3.2726'}
Epoch: 2 - Metrics: {'loss': '0.5326', 'median_absolute': '0.7299', 'val_loss': '0.5381'}
Epoch: 3 - Metrics: {'loss': '0.1544', 'median_absolute': '0.3754', 'val_loss': '0.1464'}
Epoch: 4 - Metrics: {'loss': '0.0719', 'median_absolute': '0.1923', 'val_loss': '0.0682'}
Epoch: 5 - Metrics: {'loss': '0.0345', 'median_absolute': '0.1322', 'val_loss': '0.0335'}
Epoch: 6 - Metrics: {'loss': '0.1456', 'median_absolute': '0.2241', 'val_loss': '0.1374'}
Epoch: 7 - Metrics: {'loss': '0.0377', 'median_absolute': '0.1267', 'val_loss': '0.0414'}
Epoch: 8 - Metrics: {'loss': '0.0344', 'median_absolute': '0.1129', 'val_loss': '0.0334'}
Epoch: 9 - Metrics: {'loss': '0.0217', 'median_absolute': '0.0981', 'val_loss': '0.0232'}
Epoch: 10 - Metrics: {'loss': '0.0194', 'median_absolute': '0.0884', 'val_loss': '0.0227'}
Epoch: 11 - Metrics: {'loss': '0.0226', 'median_absolute': '0.0912', 'val_loss': '0.0233'}
Epoch: 12 - Metrics: {'loss': '0.0189', 'median_absolute': '0.0884', 'val_loss': '0.0212'}
Epoch: 13 - Metrics: {'loss': '0.0178', 'median_absolute': '0.0868', 'val_loss': '0.0204'}
Epoch: 14 - Metrics: {'loss': '0.0175', 'median_absolute': '0.0864', 'val_loss': '0.0170'}
Epoch: 15 - Metrics: {'loss': '0.0259', 'median_absolute': '0.1085', 'val_loss': '0.0254'}
Epoch: 16 - Metrics: {'loss': '0.0251', 'median_absolute': '0.0952', 'val_loss': '0.0254'}
Epoch: 17 - Metrics: {'loss': '0.0226', 'median_absolute': '0.0932', 'val_loss': '0.0272'}
Epoch: 18 - Metrics: {'loss': '0.0224', 'median_absolute': '0.0985', 'val_loss': '0.0233'}
Epoch: 19 - Metrics: {'loss': '0.0240', 'median_absolute': '0.0994', 'val_loss': '0.0231'}
Epoch: 20 - Metrics: {'loss': '0.0209', 'median_absolute': '0.0947', 'val_loss': '0.0214'}
Epoch: 21 - Metrics: {'loss': '0.0153', 'median_absolute': '0.0797', 'val_loss': '0.0179'}
Epoch: 22 - Metrics: {'loss': '0.0212', 'median_absolute': '0.0891', 'val_loss': '0.0211'}
Epoch: 23 - Metrics: {'loss': '0.0161', 'median_absolute': '0.0862', 'val_loss': '0.0190'}
Epoch: 24 - Metrics: {'loss': '0.0151', 'median_absolute': '0.0797', 'val_loss': '0.0167'}
Epoch: 25 - Metrics: {'loss': '0.0228', 'median_absolute': '0.0986', 'val_loss': '0.0247'}
Epoch: 26 - Metrics: {'loss': '0.0213', 'median_absolute': '0.0991', 'val_loss': '0.0221'}
Epoch: 27 - Metrics: {'loss': '0.0203', 'median_absolute': '0.0921', 'val_loss': '0.0217'}
Epoch: 28 - Metrics: {'loss': '0.0144', 'median_absolute': '0.0772', 'val_loss': '0.0182'}
Epoch: 29 - Metrics: {'loss': '0.0337', 'median_absolute': '0.1290', 'val_loss': '0.0430'}
Epoch: 30 - Metrics: {'loss': '0.0191', 'median_absolute': '0.0924', 'val_loss': '0.0226'}
Epoch: 31 - Metrics: {'loss': '0.0218', 'median_absolute': '0.0981', 'val_loss': '0.0260'}
Epoch: 32 - Metrics: {'loss': '0.0382', 'median_absolute': '0.1222', 'val_loss': '0.0374'}
Epoch: 33 - Metrics: {'loss': '0.0188', 'median_absolute': '0.0908', 'val_loss': '0.0248'}
Epoch: 34 - Metrics: {'loss': '0.0179', 'median_absolute': '0.0914', 'val_loss': '0.0191'}
Epoch: 35 - Metrics: {'loss': '0.0457', 'median_absolute': '0.1262', 'val_loss': '0.0416'}
Epoch: 36 - Metrics: {'loss': '0.0279', 'median_absolute': '0.1119', 'val_loss': '0.0319'}
Epoch: 37 - Metrics: {'loss': '0.0233', 'median_absolute': '0.0999', 'val_loss': '0.0238'}
Epoch: 38 - Metrics: {'loss': '0.0253', 'median_absolute': '0.1230', 'val_loss': '0.0286'}
Epoch: 39 - Metrics: {'loss': '0.0178', 'median_absolute': '0.0915', 'val_loss': '0.0188'}
Epoch: 40 - Metrics: {'loss': '0.0172', 'median_absolute': '0.0863', 'val_loss': '0.0197'}
Epoch: 41 - Metrics: {'loss': '0.0195', 'median_absolute': '0.0851', 'val_loss': '0.0234'}
Epoch: 42 - Metrics: {'loss': '0.0152', 'median_absolute': '0.0857', 'val_loss': '0.0157'}
Epoch: 43 - Metrics: {'loss': '0.0200', 'median_absolute': '0.1011', 'val_loss': '0.0212'}
Epoch: 44 - Metrics: {'loss': '0.0312', 'median_absolute': '0.1182', 'val_loss': '0.0328'}
Epoch: 45 - Metrics: {'loss': '0.0187', 'median_absolute': '0.0934', 'val_loss': '0.0180'}
Epoch: 46 - Metrics: {'loss': '0.0186', 'median_absolute': '0.0985', 'val_loss': '0.0203'}
Epoch: 47 - Metrics: {'loss': '0.0371', 'median_absolute': '0.1470', 'val_loss': '0.0392'}
Epoch: 48 - Metrics: {'loss': '0.0674', 'median_absolute': '0.1752', 'val_loss': '0.0725'}
Epoch: 49 - Metrics: {'loss': '0.0266', 'median_absolute': '0.1210', 'val_loss': '0.0267'}
Epoch: 50 - Metrics: {'loss': '0.0167', 'median_absolute': '0.0848', 'val_loss': '0.0200'}
import torch
import matplotlib.pyplot as plt
from DLL.DeepLearning.Model import Model
from DLL.DeepLearning.Layers import Dense, Identity, Add
from DLL.DeepLearning.Layers.Regularisation import BatchNorm, Dropout
from DLL.DeepLearning.Layers.Activations import Tanh, Sigmoid, ReLU
from DLL.DeepLearning.Losses import MSE
from DLL.DeepLearning.Optimisers import SGD, RMSPROP
from DLL.DeepLearning.Initialisers import Xavier_Normal, Xavier_Uniform, Kaiming_Normal, Kaiming_Uniform
from DLL.Data.Preprocessing import data_split
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = Model(2, data_type=torch.float32, device=device)
model.add(Dense(6, initialiser=Xavier_Uniform(), normalisation=BatchNorm(), activation=ReLU()))
model.add(Add(Dense(6, activation=ReLU()), Identity(), normalisation=BatchNorm()))
model.add(Dropout(p=0.1))
model.add(Dense(6, initialiser=Kaiming_Normal()))
model.add(BatchNorm())
model.add(Sigmoid())
model.add(Dense(0, initialiser=Xavier_Normal()))
# model.compile(optimiser=SGD(learning_rate=0.1), loss=MSE(), metrics=["loss", "val_loss", "median_absolute"])
model.compile(optimiser=RMSPROP(learning_rate=0.01), loss=MSE(), metrics=["loss", "val_loss", "median_absolute"])
model.summary()
n = 30
X, Y = torch.meshgrid(torch.linspace(-1, 1, n, dtype=torch.float32, device=device), torch.linspace(-1, 1, n, dtype=torch.float32, device=device), indexing="xy")
x = torch.stack((X.flatten(), Y.flatten()), dim=1)
y = X.flatten() ** 2 + Y.flatten() ** 2 + 0.1 * torch.randn(size=Y.flatten().size(), device=device) - 5
x_train, y_train, x_val, y_val, x_test, y_test = data_split(x, y, train_split=0.6, validation_split=0.2)
errors = model.fit(x_train, y_train, val_data=(x_val, y_val), epochs=50, batch_size=64, verbose=True)
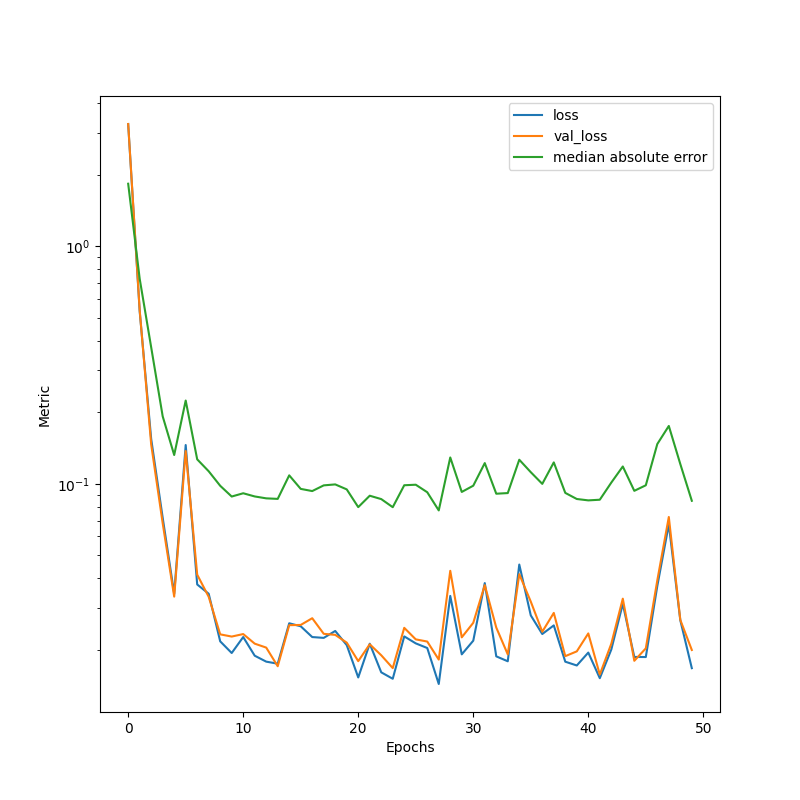
plt.figure(figsize=(8, 8))
plt.semilogy(errors["loss"], label="loss")
plt.semilogy(errors["val_loss"], label="val_loss")
plt.semilogy(errors["median_absolute"], label="median absolute error")
plt.legend()
plt.xlabel("Epochs")
plt.ylabel("Metric")
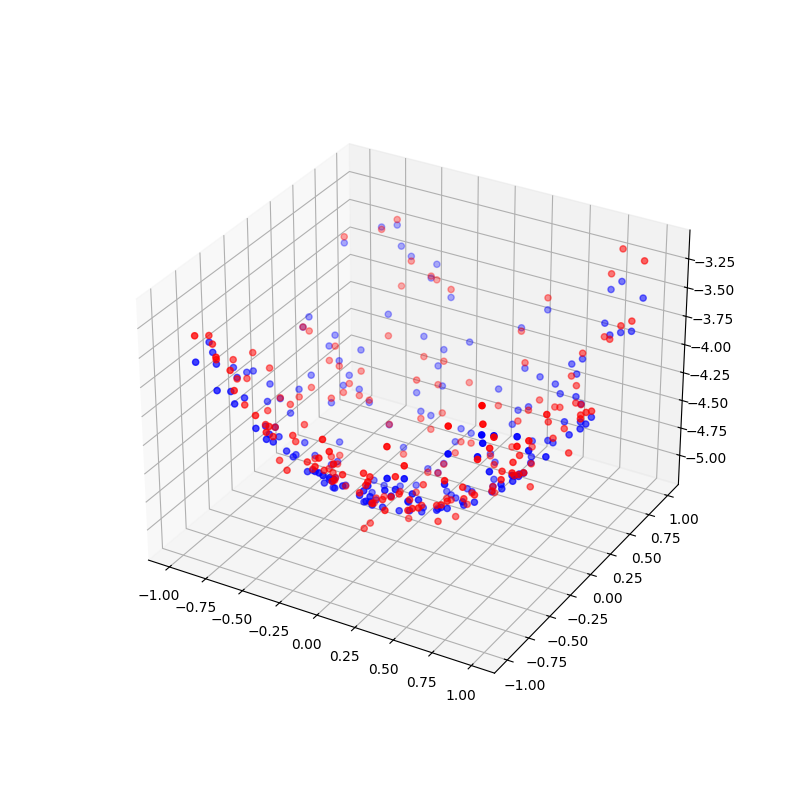
z = model.predict(x_test).cpu().numpy()
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
surf = ax.scatter(x_test[:, 0].cpu().numpy(), x_test[:, 1].cpu().numpy(), z, color="blue")
surf = ax.scatter(x_test[:, 0].cpu().numpy(), x_test[:, 1].cpu().numpy(), y_test.cpu().numpy(), color="red")
plt.show()
Total running time of the script: (0 minutes 1.058 seconds)