Note
Go to the end to download the full example code.
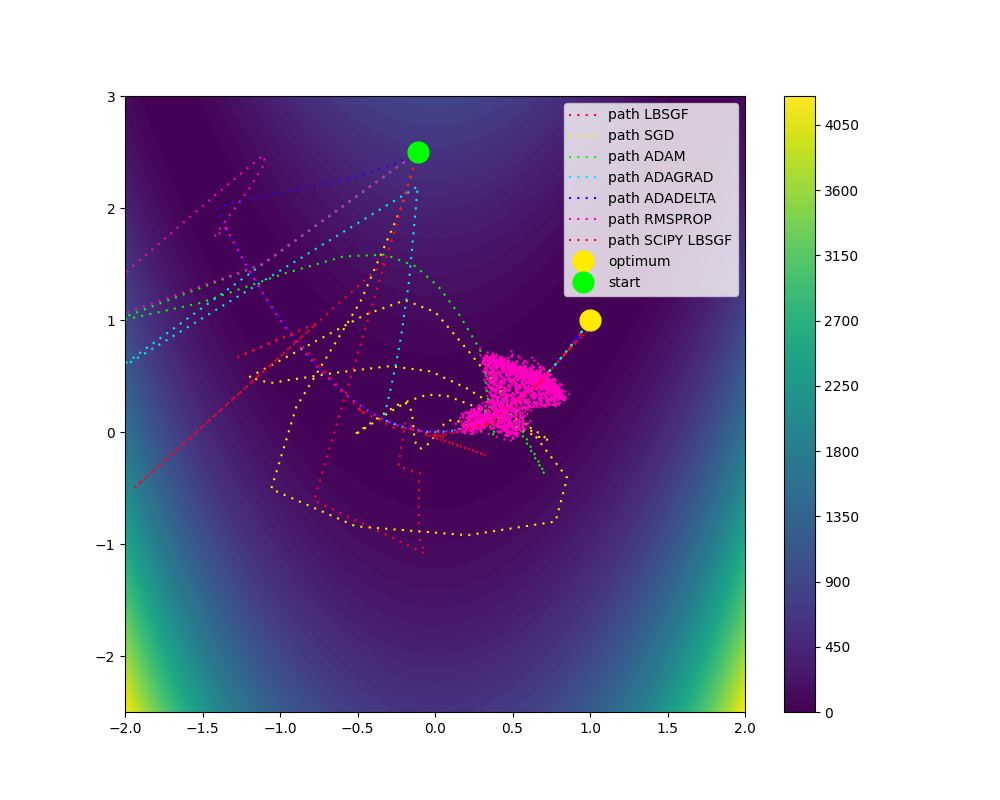
Comparison of Optimization Algorithms on the Rosenbrock Function
This script demonstrates the performance of various optimization algorithms in minimizing the Rosenbrock function, a well-known test problem in optimization.
- Optimization Algorithms from DLL.DeepLearning.Optimisers:
LBFGS (Limited-memory BFGS)
SGD (Stochastic Gradient Descent)
ADAM (Adaptive Moment Estimation)
ADAGRAD (Adaptive Gradient Algorithm)
ADADELTA (Adaptive Delta)
RMSPROP (Root Mean Square Propagation)
BFGS (Broyden-Fletcher-Goldfarb-Shanno Algorithm)
import torch
import matplotlib.pyplot as plt
from scipy.optimize import minimize
import numpy as np
from DLL.DeepLearning.Optimisers import LBFGS, ADAM, SGD, ADAGRAD, ADADELTA, RMSPROP, BFGS
torch.set_printoptions(sci_mode=False)
def f(x):
return (1 - x[0]) ** 2 + 100 * (x[1] - x[0] ** 2) ** 2
def f_prime(x):
return torch.tensor([-2 * (1 - x[0]) - 400 * x[0] * (x[1] - x[0] ** 2), 200 * (x[1] - x[0] ** 2)], dtype=x.dtype)
# def f(x):
# return x[0] ** 2 + x[1] ** 2
# def f_prime(x):
# return torch.tensor([2 * x[0], 2 * x[1]], dtype=x.dtype)
initial_point = [-0.11, 2.5]
x1 = torch.tensor(initial_point, dtype=torch.float32)
x2 = torch.tensor(initial_point, dtype=torch.float32)
x3 = torch.tensor(initial_point, dtype=torch.float32)
x4 = torch.tensor(initial_point, dtype=torch.float32)
x5 = torch.tensor(initial_point, dtype=torch.float32)
x6 = torch.tensor(initial_point, dtype=torch.float32)
x7 = torch.tensor(initial_point, dtype=torch.float32)
optimiser1 = LBFGS(lambda: f(x1), history_size=10, maxiterls=20)
optimiser2 = SGD(learning_rate=0.001)
optimiser3 = ADAM(learning_rate=1.1, amsgrad=True)
optimiser4 = ADAGRAD(learning_rate=1.2)
optimiser5 = ADADELTA(learning_rate=10, rho=0.7)
optimiser6 = RMSPROP(learning_rate=0.2, momentum=0.5)
optimiser7 = BFGS(lambda: f(x7), maxiterls=20)
optimiser1.initialise_parameters([x1])
optimiser2.initialise_parameters([x2])
optimiser3.initialise_parameters([x3])
optimiser4.initialise_parameters([x4])
optimiser5.initialise_parameters([x5])
optimiser6.initialise_parameters([x6])
optimiser7.initialise_parameters([x7])
# with 30 iterations, LBFGS algorithms (my and scipy) converge, while ADAM and SGD converge with around 1000 iterations using initial_point == [-0.11, 2.5]. ADAGRAD takes around 5000.
max_iter = 30
max_iter = 5000
points1 = [x1.clone()]
points2 = [x2.clone()]
points3 = [x3.clone()]
points4 = [x4.clone()]
points5 = [x5.clone()]
points6 = [x6.clone()]
points7 = [x7.clone()]
for epoch in range(max_iter):
optimiser1.zero_grad()
optimiser2.zero_grad()
optimiser3.zero_grad()
optimiser4.zero_grad()
optimiser5.zero_grad()
optimiser6.zero_grad()
optimiser7.zero_grad()
x1.grad += f_prime(x1)
x2.grad += f_prime(x2)
x3.grad += f_prime(x3)
x4.grad += f_prime(x4)
x5.grad += f_prime(x5)
x6.grad += f_prime(x6)
x7.grad += f_prime(x7)
optimiser1.update_parameters()
optimiser2.update_parameters()
optimiser3.update_parameters()
optimiser4.update_parameters()
optimiser5.update_parameters()
optimiser6.update_parameters()
optimiser7.update_parameters()
points1.append(x1.clone())
points2.append(x2.clone())
points3.append(x3.clone())
points4.append(x4.clone())
points5.append(x5.clone())
points6.append(x6.clone())
points7.append(x7.clone())
scipy_points = []
def scipy_func(x):
scipy_points.append(x)
return (1 - x[0]) ** 2 + 100 * (x[1] - x[0] ** 2) ** 2
# def scipy_func(x):
# scipy_points.append(x)
# return x[0] ** 2 + x[1] ** 2
minimize(scipy_func, initial_point, method="L-BFGS-B", options={"maxiter": max_iter}) # options={"maxls": 1, "maxiter": max_iter}
colors = plt.cm.gist_rainbow(np.linspace(0, 1, 6))
plt.rcParams['axes.prop_cycle'] = plt.cycler(color=colors)
points1 = torch.stack(points1)
points2 = torch.stack(points2)
points3 = torch.stack(points3)
points4 = torch.stack(points4)
points5 = torch.stack(points5)
points6 = torch.stack(points6)
points7 = torch.stack(points7)
scipy_points = np.stack(scipy_points)
names = ["LBFGS", "SGD", "ADAM", "ADAGRAD", "ADADELTA", "RMSPROP", "BFGS", "Scipy LBFGSB"]
optimum_point = np.array([1.0, 1.0])
for i, points in enumerate([points1, points2, points3, points4, points5, points6, points7, scipy_points]):
if np.linalg.norm(np.asarray(points[-1]) - optimum_point) > 1e-1:
print(names[i], "failed", np.asarray(points[-1]), "!=", optimum_point)
plt.figure(figsize=(10, 8))
line_style = (0, (1, 3)) # (0, (1, 20))
marker_size = 10
plt.plot(points1[:, 0], points1[:, 1], linestyle=line_style, markersize=marker_size, label="path LBFGS")
plt.plot(points2[:, 0], points2[:, 1], linestyle=line_style, markersize=marker_size, label="path SGD")
plt.plot(points3[:, 0], points3[:, 1], linestyle=line_style, markersize=marker_size, label="path ADAM")
plt.plot(points4[:, 0], points4[:, 1], linestyle=line_style, markersize=marker_size, label="path ADAGRAD")
plt.plot(points5[:, 0], points5[:, 1], linestyle=line_style, markersize=marker_size, label="path ADADELTA")
plt.plot(points6[:, 0], points6[:, 1], linestyle=line_style, markersize=marker_size, label="path RMSPROP")
plt.plot(points7[:, 0], points7[:, 1], linestyle=line_style, markersize=marker_size, label="path BFGS")
plt.plot(scipy_points[:, 0], scipy_points[:, 1], linestyle=line_style, markersize=marker_size, label="path SCIPY LBFGSB")
plt.plot(1, 1, "o", markersize=15, label="optimum")
plt.plot(*points1[0], "o", markersize=15, label="start")
x_vals = torch.linspace(-2, 2, 100)
y_vals = torch.linspace(-2.5, 3, 100)
X, Y = torch.meshgrid(x_vals, y_vals, indexing="ij")
Z = f([X, Y])
contour = plt.contourf(X.numpy(), Y.numpy(), Z.numpy(), levels=100, cmap="viridis")
plt.colorbar(contour)
plt.legend()
plt.xlim(-2, 2)
plt.ylim(-2.5, 3)
plt.show()
Total running time of the script: (0 minutes 13.778 seconds)